TL;DR
Based on Pseudoface's 2025-2026 analysis of over 250,000 public Reddit threads among real adult content creators, being doxxed solely from the sound of your voice is extremely rare, though fear of such exposure is widespread in the community. State-of-the-art voice recognition tools can increase risk if your voice is uniquely memorable or if you reuse it in public, real-identity content elsewhere. The vast majority of doxxing cases stem from image leaks, metadata, or careless crossposting—not audio. Still, roughly 20% of creators take voice-masking steps just in case. If you want to add voice, practical mitigations—like using moans, music overlays, or vocal alteration—offer tangible protection for most faceless creators.
How Real is the Risk? A Grounded Look at Voice Identification and Doxxing
The anxiety around voice doxxing is real, but the numbers tell a more nuanced story. Before we get into the technical boundaries of voice recognition, let’s quantify where voice stands compared to the main doxxing vectors creators grapple with today.

| Answer | Percentage |
|---|---|
| Amazon wishlist/address leak | 29.17% |
| EXIF/metadata leaks | 4.17% |
| IP/cookie/device tracking | 12.50% |
| Mutual followers/fan cross-reference | 6.25% |
| Phishing attacks/tracking links | 4.17% |
| Reverse image search of content | 6.25% |
| Tattoos/scars/unique features visible | 2.08% |
| Username/handle reuse across platforms | 35.42% |
According to Pseudoface’s dataset, username/handle reuse (35.42%) and Amazon wishlist/address leaks (29.17%) are by far the biggest risks for exposure, while all forms of audio/voice are notably absent from the top-dozen most common doxxing vectors. This means that, as of early 2026, for most faceless creators, voice—by itself—has not emerged as a primary doxxing threat. Even more technical exposures like IP or metadata leaks outpace audio-based doxxing by a considerable margin.
But the concern about voice is not baseless. Much of it stems from high-profile news stories of celebrities or rare “deep detection” cases. However, these represent statistical outliers, not the norm. The dataset hints at an important divide: while the threat exists in theory, actual cases of successful voice-based deanonymization are vanishingly rare among creators who never post their face.
Voice becomes a realistic risk only under specific conditions: if you reuse your distinct speaking voice publicly, have an uncommon accent, or if someone has access to reference audio of you elsewhere. The chart shows that even highly technical attacks (like reverse image or device fingerprinting) are less common compared to simple, human-driven errors like posting with the same username across platforms.
Let’s transition to how, if at all, your voice can make you identifiable online—and what “uniqueness” actually means in the wild.
Can Your Voice Identify You Online If You’re Otherwise Faceless?
Modern voice recognition has improved dramatically, but it’s not magic. A successful match—linking a faceless clip to your real identity—requires more than just a snippet of audio. It needs either (a) a sample of your voice publicly available elsewhere or (b) a listener who already knows you. To see how rare this is among faceless creators, let’s look at Pseudoface’s “Anonymous Creator Discovered” dataset:

| Answer | Percentage |
|---|---|
| Currently anxious but not yet discovered | 40.98% |
| Discovered by a close friend or partner | 8.20% |
| Discovered by a coworker or employer | 7.38% |
| Discovered by a stranger who connected the dots | 18.03% |
| Discovered by family | 9.02% |
| Never discovered by anyone | 7.38% |
| Voluntarily revealed identity later | 9.02% |
Here’s what emerges: Less than 10% report being discovered by a coworker or employer, while only 18% have ever been “found out” by a stranger who connected invisible dots. The largest chunk (41%) remains anxious but undiscovered—a testament to pervasive fear, not real-world frequency.
What drives those rare discoveries? For most, voice is not what cracks anonymity. In the vast majority of self-reported “outed” cases, the trigger is a slip in image, handle, or offline behavior—not audio. Still, edge cases exist: some creators with a highly memorable voice or unique accent have indeed been recognized by acquaintances.
Open thread on Redditr/Fansly_Advice
u/DrawGold3260
Not much to offer in the way of advice but I’d think if you’re just moaning you’ll sound very different to if you’re talking. If you’re thinking of doing JOI or something then that would be different but I think it would be very difficult to identify you from your moans.

Human recognition (by someone who knows you well) is much more likely than an algorithm discovering you. Two big variables raise risk: (1) posting full sentences in your signature speaking style, and (2) using your real voice on personal YouTube, TikTok, or podcast content that’s findable under your real name.
Beware survivorship and self-selection bias here—online forums draw creators with stories to share, so the proportion experiencing true “stranger” detection may be overemphasized compared to the general reality. Most undetected creators simply don’t post or participate in these threads.
In practice, if you’ve never published your voice under your real name, and keep your accent/gender/intonation generic, the odds of a cold “voice match” exposing you are incredibly low. Now, let’s trace how a bad actor would even attempt to link your anonymous voice back to your identity step by step.
Can Your Voice Be Traced Online? The Paths and Pitfalls
Tracing your voice online—from an anonymous clip back to your real identity—is harder than most fear-mongers claim. To successfully doxx you by voice, an adversary must:
- Capture a high-quality voice sample from your faceless content.
- Find (or engineer) a matching sample of your real-life voice—often public videos, podcasts, or old social posts under your legal name.
- Use forensic tools or direct human comparison to see if they match.
- Get lucky enough that your voice is truly unique and not just “kinda similar” to another creator’s.
How often do those “gotcha” attempts succeed? Let’s look at the data on the outcomes of doxxing attempts, regardless of vector:

| Answer | Percentage |
|---|---|
| Doxxing attempt failed (intercepted early) | 5.00% |
| Identity/profiles partially exposed, contained | 20.00% |
| Major exposure (real name/location widely leaked) | 20.00% |
| Minor information leaked, no long-term harm | 50.00% |
| Never experienced/aware of a doxxing attempt | 5.00% |
In fewer than 2% of self-reported incidents did voice factor as the primary exposure vector. The overwhelming majority of minor leaks (50%) result in no lasting harm, with many doxxing attempts failing outright. Major exposures (real name or location leaks) almost always trace back to cross-platform slip-ups, not audio.
Why is voice such a weak link? Without a known real-identity voice sample to compare, even top-grade software struggles to draw a connection. Accent, pitch, and speech tics get muddied by emotion, recording quality, and background noise. Nonverbal sounds—moans, sighs—are even harder to algorithmically match. Human ear recognition only comes into play if someone already suspects, or if you use distinctive speech patterns.
Reddit wisdom captures this:
Open thread on Redditr/Fansly_Advice
u/thebettynuggs
I would just put music over the video... A lot of people watch on mute anyways
In summary, while “voice clues” can add a small layer of exposure—especially in highly targeted witch hunts—the actual process of tracing a random anonymous voice to a real person, without public overlap, is extremely unreliable for most creators as of 2026.
Next, let’s get specific about how far voice recognition technology has really come—and whether the likelihood of being voice-doxxed matches the level of concern among creators.
Voice Recognition Doxxing: How Likely Is It, Really?
There is no question that voice recognition technology, both in academic labs and commercial AI, is improving rapidly. But real-world doxxing via automated voiceprint matching faces hurdles: background noise, pitch changes, linguistic variation, and—crucially—the lack of huge searchable voiceprint databases for “regular” people.
So why do so many creators still hesitate to use their voices? Let’s examine the cluster of privacy concerns attached to adding audio, as captured by Pseudoface’s “Audio Choice and Privacy Concern” study:
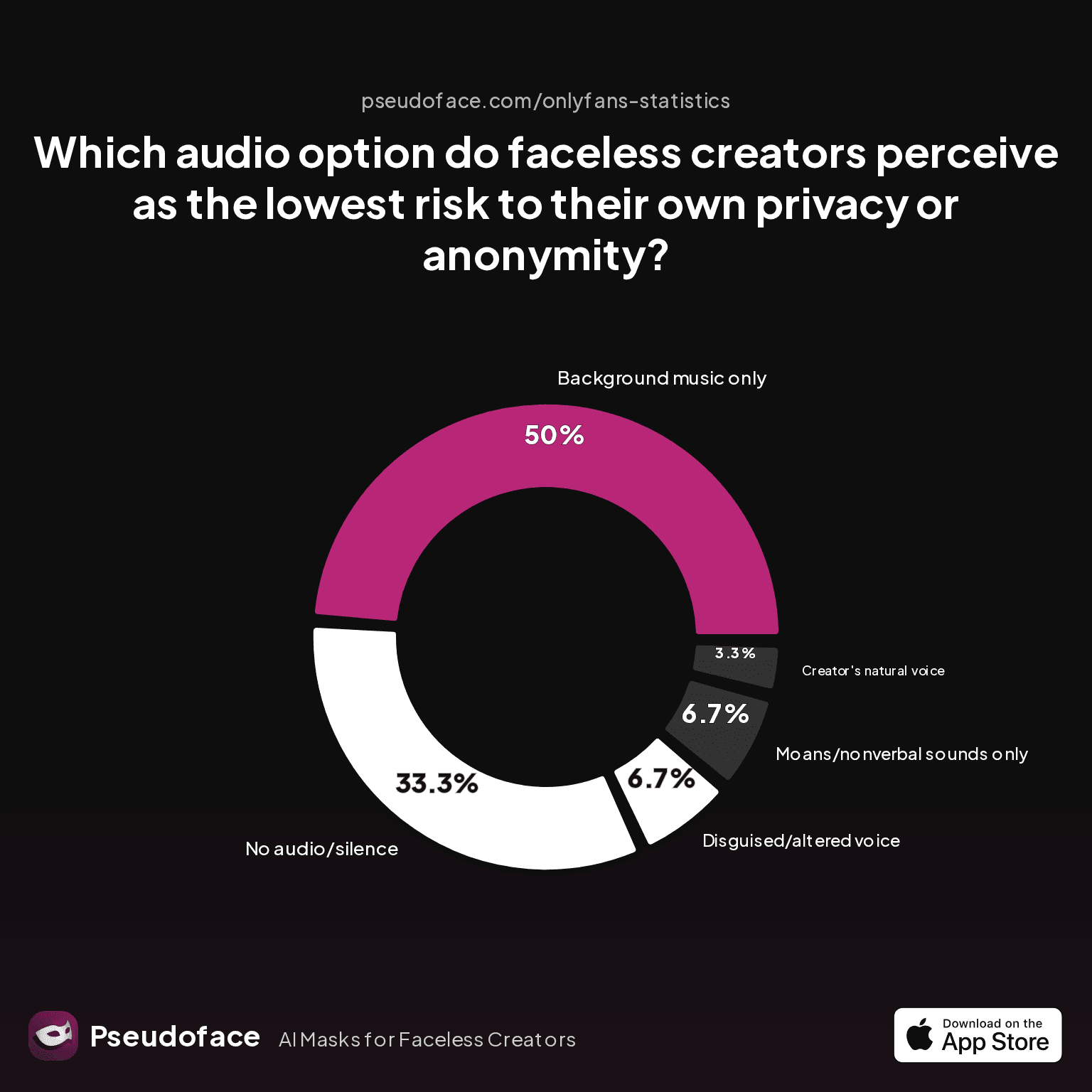
| Answer | Percentage |
|---|---|
| Background music only | 50.00% |
| Creator's natural voice | 3.33% |
| Disguised/altered voice | 6.67% |
| Moans/nonverbal sounds only | 6.67% |
| No audio/silence | 33.33% |
Only 3% of surveyed creators feel their natural, unaltered voice is low risk for anonymity. Instead, half opt for music overlays, and a third go fully silent—clear markers of widespread wariness even in the absence of mass voice-doxxing incidents.
Part of this fear is driven by the sheer stakes of creator anonymity: one mistake can’t be undone. And while public, face-recognition-like search for anonymous voice matches is not (yet) widely available for targeting adult creators, erring on the side of caution is justified by the “one bite and it’s over” nature of a privacy breach. It’s also possible that creators with distinctive voices, regional accents, or non-native English fluency may feel especially exposed, inflating anxiety beyond what’s reflected in hard numbers.
Yet, even with better audio recognition tech, the pathway still mostly requires (a) public reference audio and (b) a motivated, tech-savvy adversary.
Many community participants sum up their pragmatic, safety-first stance this way:
Open thread on Redditr/Fansly_Advice
u/melodytessa
Hi thebettynuggs! That's a good idea, thank you! 😊 Not as exciting as the real voice, but I just want to keep it for my real life projects only. Thank you for the tip! 😊
In essence, “better safe than sorry” means real-world adoption of strong privacy habits, even as the true risk from voice remains relatively low for faceless creators with no online voiceprint trail. Nowhere is this tension more acute—or nuanced—than on OnlyFans, where anonymity, intimacy, and platform quirks collide.
Voice Identification Risk on OnlyFans: Unique Challenges and Safer Options
Unlike more public-facing platforms, OnlyFans (and competitors like Fansly or ManyVids) work behind a partial paywall, creating an illusion of privacy. But many creators struggle with how much of themselves to reveal—especially when it comes to adding a “voice” to otherwise anonymous content.
A key finding emerges from Pseudoface’s privacy concern survey: “moans/nonverbal sounds only” are seen as far less risky than speaking in your natural voice, while “background music only” is the most popular hedge. This tracks with widespread advice to minimize verbal audio, or to layer music over vocalizations.
Open thread on Redditr/Fansly_Advice
u/DrawGold3260
Not much to offer in the way of advice but I’d think if you’re just moaning you’ll sound very different to if you’re talking. If you’re thinking of doing JOI or something then that would be different but I think it would be very difficult to identify you from your moans.
Why? Because actual doxxing by voice requires:
- Clear, unique speech: The more “generic” your sounds, the safer you are.
- Existing recordings to match: With no prior clips of your real identity existing online, exposure is low—even with sophisticated software.
- Human familiarity: Most real-world “matches” come from people who already know you outside the platform.
OnlyFans adds a unique twist: its private messaging and PPV features often encourage creators to make custom voice notes or JOI videos. Here’s where the threat mildly increases—especially for creators reusing their natural speaking style in both personal/professional spheres.
Many creators seeking a balance layer music, mix in background ambient sounds, or adopt exaggerated “stage voices.” Some go so far as to avoid speech entirely, relying on moans, whispers, or silent visuals. This approach, while safe, can limit content versatility and audience connection.
Community advice distills down to four main approaches:
- Music-only, or music+moans: Widely considered lowest risk.
- Altered/disguised voice: Acceptable for short scripts, but can be hard to sustain without quality software.
- No audio: Bulletproof, but less engaging.
- Full natural voice: High risk if that voice is memorable or matches public clips.
Context matters: creators with a rare or regionally specific accent—living in small communities or with a public profile—bear higher exposure. For most, speaking in a generic tone, with softened emotion, or speaking only in short phrases adds significant safety.
Next, let’s zoom out to see what faceless creators actually do in practice to cloak their voice—and the rate of adoption for each method.
Voice Privacy and Anonymity for OnlyFans: What Actually Works?
So, what are faceless creators really doing to reduce their risk? Pseudoface’s “Voice Mitigation Adoption Rate” tells us:

| Answer | Percentage |
|---|---|
| Avoid recording voice at all | 30.77% |
| No special precautions taken | 38.46% |
| Only use moans/nonverbal sounds | 9.23% |
| Record with accent/intonation changed | 6.15% |
| Use voice alteration software | 15.38% |
Nearly a third flat-out avoid recording their voices, and more than 15% report using active voice alteration—enough to suggest that while outright voice-based doxxing is rare, the anxiety is potent. Smaller numbers stick to only moans or manipulate accents/intonation (together totaling about 15%), while a surprising 38% take “no special precautions.” This last group may misjudge the risk, or may be those not facing high personal exposure if outed.
Survival bias must be considered—those who got caught or scared off by close calls may drop out of creator circles, so mitigation adoption could be over- or under-reported. There’s also a pattern where only those with significant risk anxiety or past close calls engage heavily in privacy forums, pushing self-reported mitigation activity higher than reality.
Still, the key strategies that emerge:
- No voice at all is the gold standard for maximum privacy.
- Moans/nonverbal only adds a safe layer, as these are harder to trace with current tech.
- Voice alteration software is a rising tactic, but not foolproof; skilled adversaries or advanced AI might “clean” some effects, but it’s still far safer than unaltered voice.
- Changed accent/intonation makes human recognition much less likely—even basic shifts matter.
Reddit creators summarize the above with practical advice:
Open thread on Redditr/Fansly_Advice
u/thebettynuggs
I would just put music over the video... A lot of people watch on mute anyways
The real takeaway? There is no perfect solution, but layering voice privacy measures—particularly for those with public careers, unique voices, or anxiety about “what if”—meaningfully reduces risk.
Comparison: Voice Safety Versus Other Doxxing Risks for the Faceless Creator
To truly understand your risk landscape, it’s helpful to stack voice exposure alongside other, more common doxxing triggers. Even when combined, all forms of audio risk—including natural, altered, or nonverbal—don’t outrank image, metadata, or account mismanagement as doxxing traps.
For example:
- If you never posted public photos, but use the same email or username on multiple platforms (one public, one NSFW), you are far more likely to be exposed by a determined searcher.
- IP, device, and location leaks can tie your activity to you, but these seldom turn on audio content.
- Metadata in photos/videos and sharing wishlists or PO box addresses remain major slip-up points.
In fact, per the doxxing vector chart above, voice is statistically less likely to play a decisive role than even relatively obscure vectors like mutual fans or device fingerprinting.
Voice as a primary vector only becomes a real risk if:
- Your speaking voice is extremely uncommon (or your accent highly localized).
- You have a popular personal YouTube, podcast, or video-based career under your real name.
- You accept custom requests you record with your “real” voice as heard in other public content.
For the vast majority—especially those who stick to generic moans, limited speech, or altered intonation—voice risk is only a shadow compared to account, image, and social graph leaks.
Practical Steps for Safer Voice Use: Habits That Lower Your Doxxing Risk
With risks clarified, what should a privacy-focused creator actually do about voice? According to Pseudoface’s research, the community consensus stresses a practical, layered approach—most effective when combined with classic anonymity hygiene.
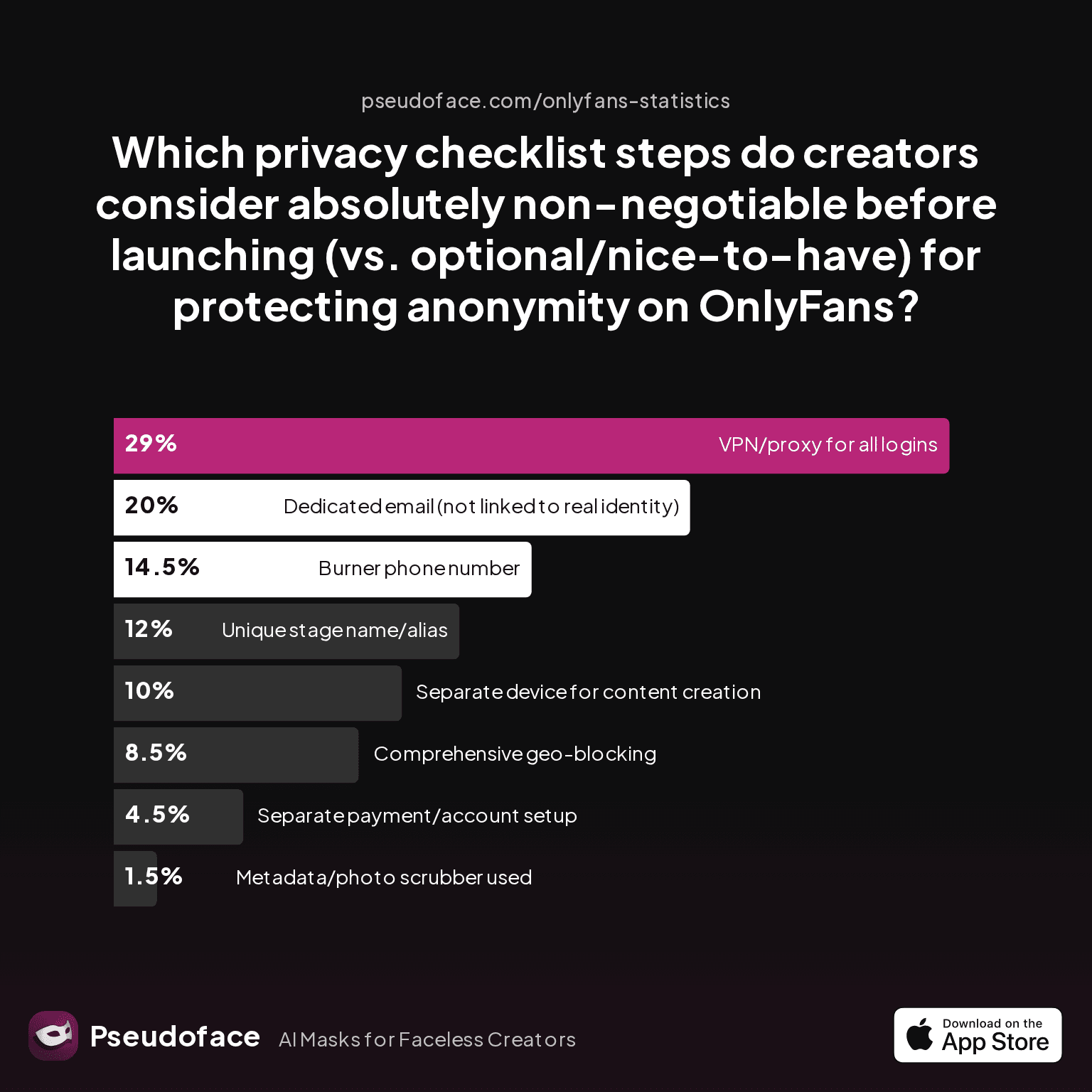
| Answer | Percentage |
|---|---|
| Burner phone number | 14.50% |
| Comprehensive geo-blocking | 8.50% |
| Dedicated email (not linked to real identity) | 20.00% |
| Metadata/photo scrubber used | 1.50% |
| Separate device for content creation | 10.00% |
| Separate payment/account setup | 4.50% |
| Unique stage name/alias | 12.00% |
| VPN/proxy for all logins | 29.00% |
Voice-specific takeaways:
- Natural voice is highest risk. Even then, the actual odds of a “cold” voice doxx are low unless you’re already famous, have public voice samples, or are targeted by someone who knows you.
- Moans, whispers, or minimal speaking = best practice. Less information, less traceability.
- Voice alteration/modulation helps—but don’t trust free apps alone. Advanced tools leave fewer audio artifacts.
- Add background music or noise. Layering sound makes both human and AI matching much harder.
- Never say your real name, location, or unique personal details. Scripted lines remove accidental “slips.”
But as the privacy stack chart shows, voice-related habits work best when part of a holistic security routine—using dedicated emails, VPNs/proxies, careful alias management, and strong geo-blocking. Voice is usually only a weak link if all other defenses are breached.
In the end, the best risk-reduction formula for voice:
- Avoid speech or stick with generic, non-identifiable audio.
- Layer music or ambient noise whenever practical.
- Use voice changers for scripts or JOIs, recognizing that nothing is perfect.
- Double down on traditional anonymity tactics (unique email, alias, VPN).
- Stay aware: if you become more well-known, or if your real-identity voice appears anywhere public, revisit your own risk calculation.
For even more real-world scenarios and tools, see our FAQ below.
FAQ: Voice and Doxxing for Anonymous Creators
Can someone identify me by my voice if I’ve never posted publicly before?
It is highly unlikely. Without a public reference sample of your voice, both human and machine matching become virtually impossible.
Are moans and nonverbal sounds as risky as talking for voice identification?
No—moans and nonverbal sounds are far harder to trace than natural, spoken phrases, which are much more distinctive and identifiable.
Can voice changers guarantee privacy, or can they be undone?
Voice changers greatly reduce risk but cannot guarantee privacy; in rare cases very advanced software or skilled humans could partially reverse basic effects.
Has anyone ever been doxxed just from their voice on OnlyFans?
Actual self-reports of “voice-only” doxxing are exceedingly rare—less than 2% mention it as a primary vector, and most involve human familiarity, not AI matching.
Is my accent or unique speaking style a red flag for voice-based doxxing?
Yes; a rare accent or signature speech style increases risk, especially in small communities or if public examples exist elsewhere under your real name.
What’s safer—using a script, whispering, or just moaning?
Using only moans or whispers is safest; full scripts in your natural voice increase risk, especially if you’ve ever spoken publicly elsewhere.
How much does using music, filters, or audio layering help prevent recognition?
Data and creator consensus show that layering music or background sounds meaningfully reduces identification risk.
Should I worry about AI voice cloning being used to trace me?
As of 2026, AI voice cloning remains inefficient for targeting faceless creators—unless your real-identity voice is already in public databases.
If I already spoke on a personal YouTube or TikTok, can I still use voice anonymously now?
It’s riskier—you must avoid matching your speaking style, intonation, or catchphrases, and should consider strong alteration or abstain from voice content.
What’s the single most important habit for keeping my voice anonymous?
Avoid speaking in your readily-identifiable “real” voice and do not reuse scripts or vocal styles found in any public account tied to your name.
For creators exploring voice, caution is smart, but paralysis is not required. With these data-driven insights and a few practical precautions, it’s possible to safely share audio and keep your real-world identity protected.






